ChecklistBank role in the data pipeline of the COL 
The ChecklistBank has a central role in the data pipeline of the COL. In the following, we are presenting the different steps in a simplified way.
The ChecklistBank has a central role in the data pipeline of the COL. In the following, we are presenting the different steps in a simplified way.
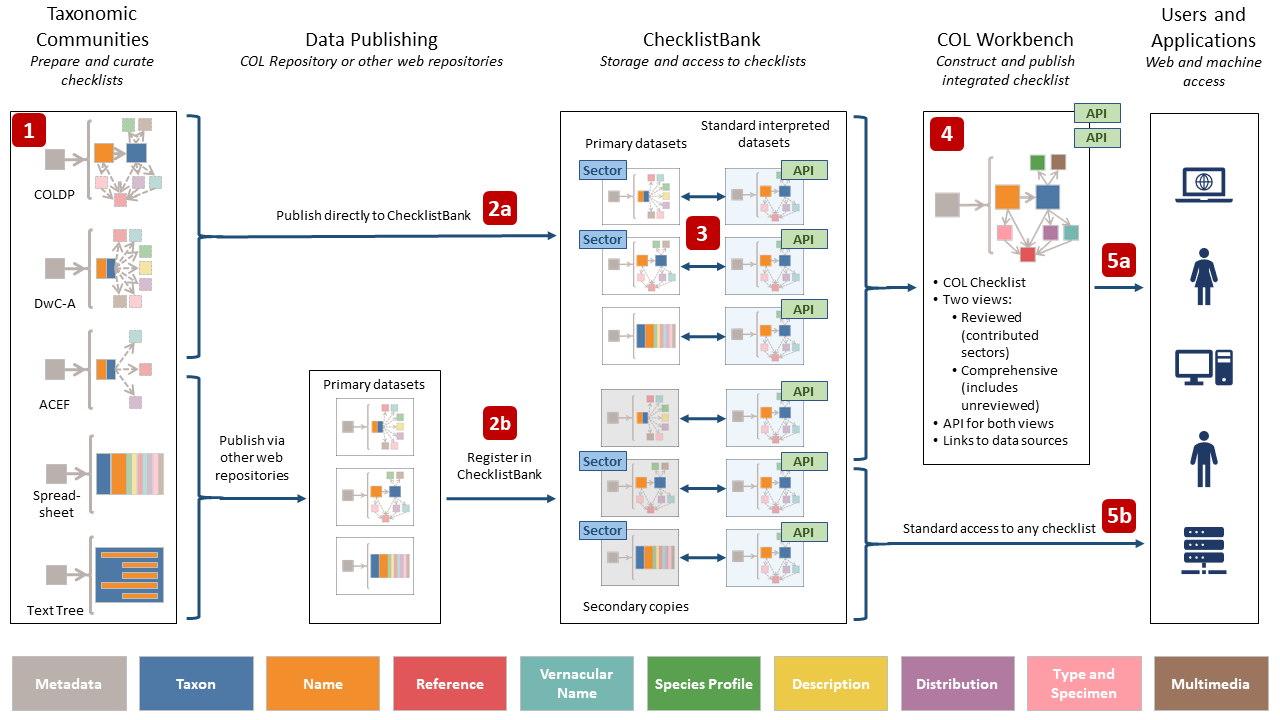
Figure 1. The five key steps in the COL Data Pipeline and the role of the ChecklistBank.
Preparing and Curating Checklists:
- People or groups create lists of species for various reasons using different tools.
- These lists can be about all species in a group, specific to a location, or based on a theme.
- The data can be simple or detailed and needs to be organized in a format recognized by the Catalogue of Life (COL).
Publishing to ChecklistBank:
- Lists can be uploaded directly to ChecklistBank or published elsewhere on the web.
- ChecklistBank ensures it has a copy for users to review and maintains it if published elsewhere.
Standard Processing:
- ChecklistBank interprets data into a standardized format called COL Data Package (ColDP).
- Both the original and interpreted versions are accessible, supporting standardized citation.
Building the COL Checklist:
- The COL Workbench tool automates creating the COL Checklist from ChecklistBank data.
- Rules define the best sectors for different groups, addressing processing issues.
- Missing taxa and names from secondary sources are added but marked as unreviewed.
- The taxonomic community reviews and endorses or rejects the additions.
Accessing and Using the Data:
- Users can access, browse, download, and cite the COL Checklist and other checklists.
- Options to view comprehensive data or content formally reviewed by a sector community.
- Historical versions are available, linking back to the source checklists in ChecklistBank.
Scenario of use of the ChecklistBank
Dr. Elena is using ChecklistBank in the Catalogue of Life pipeline for a study on invasive plant species in the Mediterranean Basin.
Background: Dr. Elena is a botanist specializing in invasive species ecology. She's starting a project aimed at updating the list of non-native plant species in the Mediterranean region, assessing their impact on local ecosystems, and informing policy decisions on biodiversity conservation.
Step 1: Defining the Objective Dr. Elena's primary goal is to identify all non-native plant species reported in the Mediterranean Basin. She needs a comprehensive checklist that includes the most recent and historically documented data.
Step 2: Accessing ChecklistBank Dr. Elena visits the Catalogue of Life website and navigates to the ChecklistBank section. She's looking for existing checklists related to her area of interest that she can use as a foundation for her study.
Step 3: Searching for Checklists Using the search functionality of ChecklistBank, she enters keywords such as "Mediterranean," "invasive plants," and "non-native flora." The search results return several relevant checklists, including one titled "Non-native Plant Species in the Mediterranean Basin."
Step 4: Reviewing and Analyzing Data She reviews the checklists and selects the most relevant ones. Dr. Elena downloads the data in a format compatible with her data analysis tools, like CSV for spreadsheet applications or Darwin Core for specialized biodiversity informatics tools.
Step 5: Field Verification With the preliminary checklist on hand, Dr. Elena conducts field research, surveying several sites across the Mediterranean Basin, collecting samples, and recording sightings of invasive species.
Step 6: Data Comparison and Synthesis After collecting field data, she compares her findings with the data from ChecklistBank. Dr. Elena updates the checklist with any new invasive species she observed and notes any discrepancies in species classification or distribution.
Step 7: Submitting Updates to ChecklistBank Dr. Elena prepares her new data in the format required by ChecklistBank. She includes taxonomic revisions, new species records, and updates on species distributions. She submits this data through the portal's submission form, contributing to the global effort of tracking invasive species.
Step 8: Collaboration and Review After submission, her data goes through a review process by taxonomic experts associated with the Catalogue of Life. There might be a back-and-forth communication to ensure the accuracy and clarity of the new data.
Step 9: Publication and Citation Upon validation, Dr. Elena's updated checklist is published within ChecklistBank. She then uses the updated and expanded checklist as a reference for her scientific papers, citing the Catalogue of Life as a source. She includes a digital object identifier (DOI) provided by ChecklistBank for each checklist used.
Step 10: Informing Policy and Conservation Measures Finally, Dr Elena's work, augmented by the authoritative data from ChecklistBank, is used by environmental policymakers to make informed decisions regarding the management of invasive species in the Mediterranean. It helps identify priority areas for conservation efforts and formulate strategies to prevent the spread of invasive species.
Outcome: Dr. Elena's research not only contributes to the scientific community by providing an updated resource on invasive plants but also assists in the development of more effective conservation policies. The checklist data from ChecklistBank is central to understanding changes in biodiversity and guiding measures to protect native species and ecosystems.
Additional Materials and Related Information
To get an idea of the integrated process (COL Data Pipeline) have a look at this resource. The ChecklistBank tutorial provides some exercises to explore the tools it offers.

An introductory presentation to ChecklistBank is available here.
ChecklistBank synchronises with the GBIF registry every 3 hours. As part of this synchronisation, datasets from TreatmentBank are imported into ChecklistBank. At present, more than 46K datasets, mostly originating from TreatmentBank, and also direct from the Biodiversity Data Journal of Pensoft, are made available through ChecklistBank. This also includes datasets originating from other journals Pensoft Publishers and the European Journal of Taxonomy, amongst others. The number of datasets from TreatmentBank in ChecklistBank is gradually increasing with about 1K datasets per month.